125 lines
7.1 KiB
Markdown
125 lines
7.1 KiB
Markdown
### 分隔符与解析表达式语法
|
||
|
||
我们最终选择尝试寻找一种方法,在保留现有HTML语法规范性、明确性和无歧义性的基础上进行创新。在HTML体系内,我们拥有多种可行方案。
|
||
|
||
在这些方案中,有人提出了一种新颖思路:通过将数据存储在HTML注释中,既能确保不破坏文档中原有的HTML结构,又能保证浏览器会忽略这些内容,同时还能简化文档解析流程。
|
||
|
||
HTML注释的独特之处在于它们不会合法存在于模糊位置——比如像`<img alt='data-id="14"'>`这样的HTML属性内部。注释语法还具有高度包容性:解析HTML属性需要复杂处理,而注释规则却极其简单——以`<!--`起始,中间可包含除`-->`外的任意内容,直至遇到首个`-->`结束。这种简洁性与包容性意味着解析器可以通过多种方式实现,且无需深入理解HTML语法,我们还能在注释中自由使用更便捷的语法——仅需转义双连字符序列即可。我们在存储块属性时充分利用了这一特性:将JSON字面量直接嵌入注释。
|
||
|
||
经过解析器处理后,我们获得了可直接操作的标准对象,无需担心数据转义或反转义问题——序列化过程已自动处理这些细节。由于注释与其他HTML标签存在显著差异,加之我们可以通过首轮解析提取顶层块,实际上并不需要完全有效的HTML文档!
|
||
|
||
这对解析器的简洁性与性能表现具有重大意义。这些明确的分界符还能防止单个块的损坏蔓延至其他块或污染整个文档。系统也得以在渲染前识别出未知块。
|
||
|
||
*注:* 块的核心特征在于其语义与提供的隔离机制,即其身份标识。而数据存储位置则具有更高灵活性。块不仅支持静态本地数据(通过HTML注释中的JSON字面量或块内HTML实现),未来还将支持更多机制(例如全局块或辅助存储于`WP_Post`对象)。详见[属性说明](/docs/reference-guides/block-api/block-attributes.md)。
|
||
|
||
### 序列化块的解剖结构
|
||
|
||
当块在编辑会话结束后保存至内容时,其属性会根据块特性被序列化为这些显式注释分隔符:
|
||
|
||
```html
|
||
<!-- wp:image -->
|
||
<figure class="wp-block-image"><img src="source.jpg" alt="" /></figure>
|
||
<!-- /wp:image -->
|
||
```
|
||
|
||
对于需服务器预渲染的纯动态块,其形态可能如下:
|
||
|
||
```html
|
||
<!-- wp:latest-posts {"postsToShow":4,"displayPostDate":true} /-->
|
||
```
|
||
|
||
## 数据生命周期
|
||
|
||
总而言之,区块编辑器工作流通过词法分隔符辅助,将已保存文档解析为内存中的块树结构。编辑过程中的所有操作都在块树内部进行,最终通过将块序列化回`post_content`完成流程。
|
||
|
||
该工作流依赖序列化/解析器组合来实现文章持久化。理论上,文章数据结构既可通过插件存储,也可从远程JSON文件获取后转换为块树结构。
|
||
|
||
# 数据流与数据格式
|
||
|
||
## 格式规范
|
||
|
||
区块编辑器文章是具备区块感知能力的文章表征形式:由一系列语义一致的描述构成,阐明每个区块的定义及其核心数据。这种表征仅存在于内存中,如同排版工坊中的[活字追排](https://zh.wikipedia.org/wiki/%E6%8E%92%E7%89%88#%E6%B4%BB%E5%AD%97%E6%8E%92%E7%89%88),随着[字模](https://zh.wikipedia.org/wiki/%E5%AD%97%E6%A8%A1)的嵌入与重新定位而持续变化。
|
||
|
||
区块编辑器文章并非其最终产物——即`post_content`(文章内容)。后者如同印刷成品,为读者优化呈现的同时,仍保留着用于后续编辑的隐形标记。
|
||
|
||
区块编辑器的输入与输出采用当前格式的区块对象树:
|
||
|
||
```js
|
||
const value = [ block1, block2, block3 ];
|
||
```
|
||
|
||
### 区块对象
|
||
|
||
每个区块对象包含唯一标识符、属性集合及可能的子区块列表。
|
||
|
||
```js
|
||
const block = {
|
||
clientId, // 唯一字符串标识符
|
||
type, // 区块类型(段落、图片等)
|
||
attributes, // 代表当前区块直接属性/内容的键值对集合
|
||
innerBlocks, // 子区块或内部区块数组
|
||
};
|
||
```
|
||
|
||
需注意属性键名与类型、允许嵌套的区块均由区块类型定义。例如核心引用区块包含字符串类型的`cite`属性表示引用来源,而标题区块则包含数值型`level`属性表示标题层级(1至6级)。
|
||
|
||
在编辑器的区块生命周期中,区块对象可接收额外元数据:
|
||
|
||
- `isValid`:布尔值,标识区块是否有效
|
||
- `originalContent`:区块原始HTML序列化内容
|
||
|
||
**示例**
|
||
|
||
```js
|
||
// 简单段落区块
|
||
const paragraphBlock1 = {
|
||
clientId: '51828be1-5f0d-4a6b-8099-f4c6f897e0a3',
|
||
type: 'core/paragraph',
|
||
attributes: {
|
||
content: '这是段落区块的<strong>内容</strong>',
|
||
dropCap: true,
|
||
},
|
||
};
|
||
|
||
// 分隔符区块
|
||
const separatorBlock = {
|
||
clientId: '51828be1-5f0d-4a6b-8099-f4c6f897e0a4',
|
||
type: 'core/separator',
|
||
attributes: {},
|
||
};
|
||
|
||
// 包含双栏段落区块的列区块
|
||
const columnsBlock = {
|
||
clientId: '51828be1-5f0d-4a6b-8099-f4c6f897e0a7',
|
||
type: 'core/columns',
|
||
attributes: {},
|
||
innerBlocks: [
|
||
{
|
||
clientId: '51828be1-5f0d-4a6b-8099-f4c6f897e0a5',
|
||
type: 'core/column',
|
||
attributes: {},
|
||
innerBlocks: [ paragraphBlock1 ],
|
||
},
|
||
{
|
||
clientId: '51828be1-5f0d-4a6b-8099-f4c6f897e0a6',
|
||
type: 'core/column',
|
||
attributes: {},
|
||
innerBlocks: [ paragraphBlock2 ],
|
||
},
|
||
],
|
||
};
|
||
```
|
||
|
||
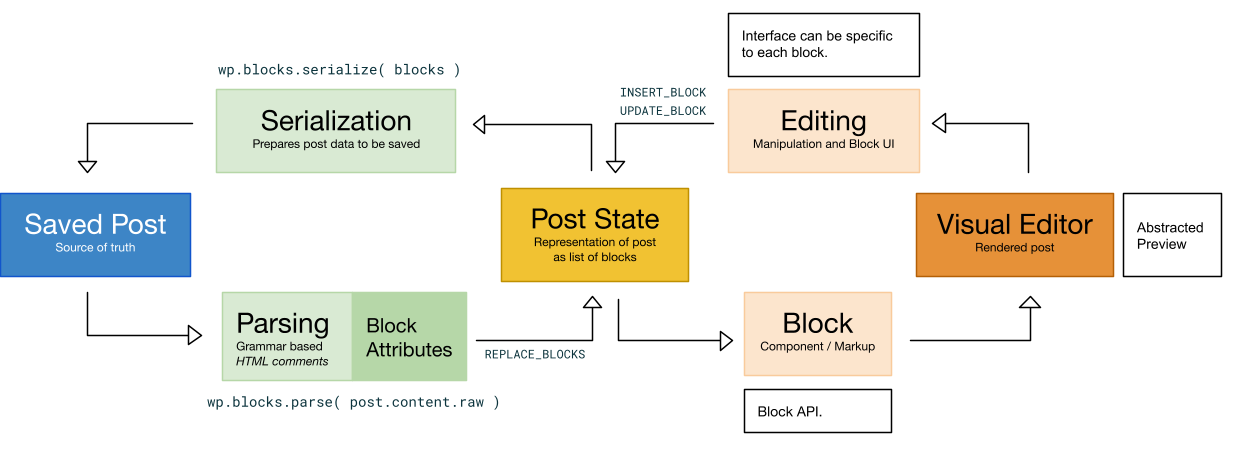
## 序列化与解析
|
||
|
||
|
||
|
||
需要注意的是,这种数据模型仅在文章编辑过程中存在于内存中。页面最终渲染时对浏览者不可见,正如印刷成品不会显露印刷机上字母的组成结构。
|
||
|
||
鉴于整个WordPress生态在渲染或编辑文章时期望接收HTML格式,区块编辑器通过序列化将其数据转换为可保存至`post_content`的形式。这确保了内容存在单一可信源,且该源始终保持可读性并与当前所有WordPress内容交互工具兼容。若将对象树单独存储,我们将面临`post_content`与对象树失步的风险,以及数据在两地重复存储的问题。
|
||
|
||
因此,序列化过程使用HTML注释作为显式区块定界符(其中可包含非HTML格式的属性),将区块树转换为HTML。这一过程如同在印刷页面上留下隐形标记,为原始结构化意图保留痕迹。
|
||
|
||
这是流程的一端。另一端则关乎如何在下一次编辑时重建区块集合。正如通过基本规则定义如何将树转换为类HTML字符串,形式化语法定义了应如何加载区块编辑器文章的序列化表征。区块编辑器文章并非为手动编辑而设计,亦非作为HTML文档进行编辑——因为其本质并非HTML。
|
||
|
||
它们只是恰巧以无需传统系统转换即可直接查看的方式存储在`post_content`中。诚然,在没有相应机制的情况下将存储的HTML加载至浏览器可能会影响体验:若包含动态内容区块,动态元素可能无法加载,服务器生成的内容可能无法显示,交互内容可能保持静态。但至少这确保了在未启用区块功能的主题和环境中仍可查看区块编辑器文章,并提供了最便捷的内容访问方式。换言之,即使保存的HTML按原样渲染,文章内容仍能基本保持完整。 |